Organization are quickly embracing Artificial Intelligence (AI), Machine Learning and Deep Learning to open new opportunities and accelerate business growth. AI Workloads, however, require massive compute power and has led to the proliferation of GPU acceleration in addition to traditional CPU power. This has led to a break in the traditional data center architecture and amplification of organizational silos, poor utilization and lack of agility. While virtualization technologies have proven themselves in the enterprise with cost effective, scalable and reliable IT computing, Machine Learning infrastructure however has not evolved and is still bound to dedicating physical resources to optimize and reduce training times.
1.1 VMware Bitfusion
Contents
VMware Bitfusion extends the power of VMware vSphere’s virtualization technology to GPUs. VMware Bitfusion helps enterprises disaggregate the GPU compute and dynamically attach GPUs anywhere in the datacenter. Support more users in test and development phase. VMware Bitfusion supports CUDA frameworks and demonstrated virtualization and remote attach for all hardware. GPUs are attached based on CUDA calls at run-time, maximizing utilization of GPU servers anywhere in the network.
2.1 GPUs for Machine Learning
With the impending end to Moore’s law, the spark that is fueling the current revolution in deep learning is having enough compute horsepower to train neural-network based models in a reasonable amount of time
The needed compute horsepower is derived largely from GPUs, which NVIDIA began optimizing for deep learning since 2012. The latest GPU architecture from NVIDIA is Turing, available with the NVIDIA T4 as well as the NVIDIA RTX 6000 and RTX 8000 GPUs, which all support virtualization.

Figure 1: The NVIDIA T4 GPU
The NVIDIA® T4 GPU accelerates diverse cloud workloads, including high-performance computing, deep learning training and inference, machine learning, data analytics, and graphics. Based on the new NVIDIA Turing™ architecture and packaged in an energy-efficient 70-watt, small PCIe form factor, NVIDIA T4 is optimized for mainstream computing environments and features multi-precision Turing Tensor Cores and new RT Cores. Combined with accelerated containerized GPU optimized software stacks from NGC, NVIDIA T4 delivers revolutionary performance at scale. (Source: NVIDIA )
2.2 NVIDIA Virtual Compute Server
NVIDIA Virtual Compute Server (vComputeServer) software uses the power of NVIDA GPUs, like the NVIDIA T4 Tensor Core GPU, to accelerate AI, machine learning, deep learning, and HPC workloads in virtual machines. vComputeServer enables NVIDIA NGC GPU-optimized containers and pre-trained models to run in a virtualized environment.
3.1 Case for Distributed Machine Learning
Advances in machine learning techniques has fueled the demand for artificial intelligence over the last decade. The quality of the prediction for complex applications require the use of a substantial amount of training data. Even though smaller machine learning models can be trained with modest amounts of data, the data and its memory requirements for training of larger models such as neural networks exponentially grow with the number of parameters. More and more GPUs are packed into physical servers to provide processing capabilities for these larger models. But his proposition is very expensive and not optimal. The paradigm for machine learning is shifting to provide the ability to scale out the processing and distributing the workload across multiple machines.
3.2 Distributed TensorFlow:
In 2017, Facebook released a paper outlining the methods they had used to reduce training time for a convolutional neural network with RESNET-50 on ImageNet from two weeks to one hour, using 256 GPUs spread over 32 servers. They had introduced a technique to train convolutional neural networks (ConvNets) across small batches. This showed that distributed training can be scaled out across different workers with their own GPU resources using TensorFlow. Distributed TensorFlow can help massively reduce the time required for running experiments in parallel on GPUs distributed across multiple worker nodes.
tf.distribute.Strategy is a TensorFlow API that helps distribute training across multiple GPUs for existing models and training code with minimal code changes.
tf.distribute.Strategy was designed with the following core capabilities:
- Ease of use with support for multiple user groups like researchers, Data Scientists, etc.
- Good performance without much tuning.
- Ability to switch between different strategies.
Distributed TensorFlow can be used with high-level API frameworks and be used for any computation leveraging TensorFlow.
3.3 Kubeflow:
Kubeflow is a scalable, portable, distributed ML platform that runs and leverages all the capabilities of Kubernetes. Kubeflow can be used to manage AI operations at scale while maintaining reliability and quality. Kubeflow and Kubernetes enables consistent operations and optimizes infrastructure usage. Kubeflow enables researchers to focus on the valuable tasks of developing domain specific training models rather than confronting DevOps configuration issues. Kubeflow provides end-to-end workflows to build, train and develop a model or to create, run and explore a pipeline.
vSphere supports virtualization of the latest hardware from NVIDIA the T4 GPUs and Mellanox with their Connect X-5 RoCE. VMware Bitfusion brings the capabilities for workloads to access GPUs over the network. There is a potential to combine the benefits of VMware Bitfusion with the capabilities of these type of high-performance hardware accelerators for distributed machine learning and build a compelling solution.
4.1 Infrastructure Components of the solution
The infrastructure components are as shown. There is a compute cluster running VMware PKS Essentials and a vSphere GPU cluster with VMware Bitfusion. The entire infrastructure is interconnected via a high speed 100 GBPS fabric.

Figure 2: Logical schematic showing solution components
The GPU hosts have been setup with VMWare Bitfusion software for GPU virtualization.

Table 2: Hardware components used in the solution

Figure 3: Virtual Machine acting as the GPU server
CentOS 7.6 based virtual machines were setup and a PKS essentials cluster with one master node and four worker nodes was established. Each of the worker nodes has an NVIDIA vGPU representing an entire NVIDIA T4 GPU and are separated across the four physical nodes. PVRDMA based networking has been setup to provide for 100 Gbps capabilities for the PKS essentials virtual machines
Other important features of the solution include
- One Kubernetes pod per VM
- Pods leverage full or partial GPUs allocated to the virtual machine
- Pods packaged with TensorFlow & CUDA Libraries etc.
- NVIDIA vComputeServer for GPU virtualized of the NVIDIA T4 GPU
- High Speed Interconnect with Mellanox X-5 100 Gbps RoCE

Figure 4: Resource pool with PKS Essential master and worker compute nodes
The solution used a readily available docker image with the following components to instantiate and run Horovod on the Kubernetes infrastructure.
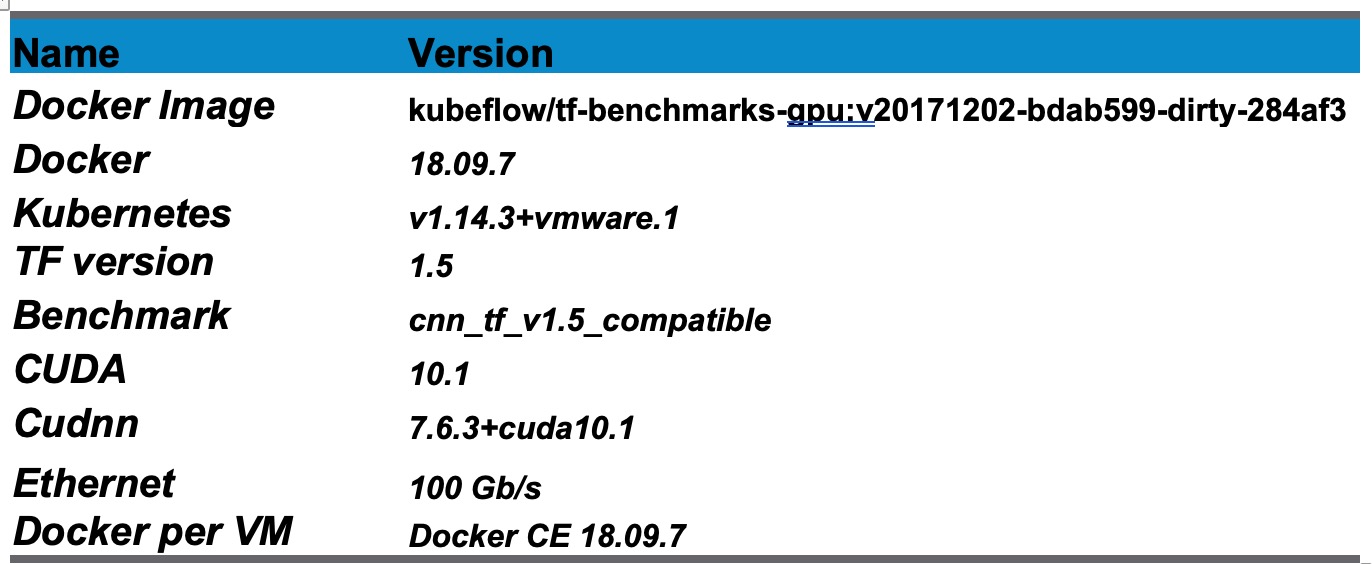

Table 2: Container & Software components used in the solution
In part 2, we will look at the testing methodology and the results. The scalability of worker nodes and fractional GPUs leveraging Bitfusion will be analyzed.





