Compute Performance is the new challenge for data analytics
Contents
Traditional enterprise databases, designed in the past century, fail to scale out effectively to meet the needs of the new streaming analytics applications. X86-based compute alone is unable to keep up with compute needs as the volume of data and its need for speedy processing have exponentially increased. New hardware acceleration techniques, along with new methodologies in data integration, modeling and optimization are increasing the need for data analytics applications to be more agile and adaptive.
Leveraging GPUs for Data Analytics
Modern GPUs (Graphical Processing Units) have thousands of cores compared to traditional CPU that have dozens of cores. They also have very significant memory bandwidth, reaching nearly 1TB/second. The combination of these two distinct advantages allow GPU-enabled hardware and software to provide supercomputer capabilities in a small, cost-effective footprint.
Tapping this potential, GPU-accelerated databases are being increasingly used to give raw, unrestricted data access to modern analytical applications and data consumers throughout various lines of business. GPUs have been known to accelerate operations that can be parallelized. While this parallelism has been adopted in Hadoop or Spark data processing (where the idea is to combine a group of database instances, each on scale-out worker nodes coordinated by a master node that delegates subqueries individually), GPU databases are capable of conducting parallel operations in a much smaller solution, because of the readily available compute power of x86 with GPU acceleration. (Source: GPU Databases coming of age )

Figure 1: NVIDIA GPUs are increasingly used for heavily parallel compute needs.
A GPU database is a database, relational or non-relational, that uses a GPU (graphical processing unit) to perform some database operations. (What is a GPU Database?) GPU databases are typically fast, geared towards analytics and use devices like NVIDIA GPUs for processing and analyzing large amounts of data for modern day applications.
It’s not as simple as just adding GPUs to your database server, because not all database operations can be parallelized. The database management system and data structures must be designed in such a way to be able to capitalize on high throughput systems, like GPUs. This is the premise on which GPU optimized databases such as SQream DB, Kinetica, OmniSci etc. are built on. Kinetica and MapD leverage in-memory storage and are usually suitable for smaller in-memory scales of data. SQream DB is built for massive data stores and is not limited by memory in the system, with advanced multi-level caches and fast GPU-accelerated compression and decompression algorithms.
3 How GPU databases work
For analytic workloads, a CPU alone may not provide the best price and performance. With the growing complexity of queries, the diversity and amount of data being processed, acceleration of query processing is critical to meet the needs of real time analytics. However, a GPU can’t function by itself, as it lacks functionality in several areas, including network and disk I/O. GPU databases often combine CPUs and GPUs to run fast SQL on big data. The combination of these two devices helps gain the maximum throughput for query processing, as shown conceptually in Figure 2.

Figure 2: Sharing compute work between GPU and CPU. Source: SQream
Validating Virtualizing GPU Database
The goal of this exercise is to validate vSphere as a viable platform for running GPU databases like SQream DB. The tests would be performed on a single SQream DB vSphere virtual machine, running against a pass-through NVIDIA Tesla P100 and 21TB of SAN (Pure M50) storage over fiber-channel. The spooling area (200 GB) would leverage NVMe (Western Digital) based local storage. We’ve selected a modified version of TPC-H, a commonly used benchmark, to validate the performance of the virtualized SQream DB instance.
Testing methodology
As described in the TPC Benchmark H (TPC-H) specification:
“TPC-H is a decision support benchmark. It consists of a suite of business-oriented ad hoc queries and concurrent data modifications. The queries and the data populating the database have been chosen to have broad industry-wide relevance. This benchmark illustrates decision support systems that examine large volumes of data, execute queries with a high degree of complexity, and give answers to critical business questions.”
As such, it is a popular metric for measuring Analytics database performance. It was also selected due to its readily available data generator, and variety of included queries, which provide good SQL syntax coverage.
The test methodology was as follows:
- The TPC-H data generator dbgen was uploaded to the VMware server, and was run over three days with scale factor 10,000, resulting in a 10TB CSV data-set.
- SQream DB v2.13.1 was installed and a storage cluster was created on the allotted /gpu_data2 drive, which has a capacity of 21TB.
Because only one GPU was available, a single SQream DB instance was used for the entirety of the test.
- Loading was performed with two different SQream DB chunk sizes, to test performance simulating different workloads.
- After loading was completed, we ran three TPC-H queries, and measured their runtime and amount of data read from disk. The queries were TPCH-1, TPC-H 8 and TPC-H 19.
Hardware and software components:
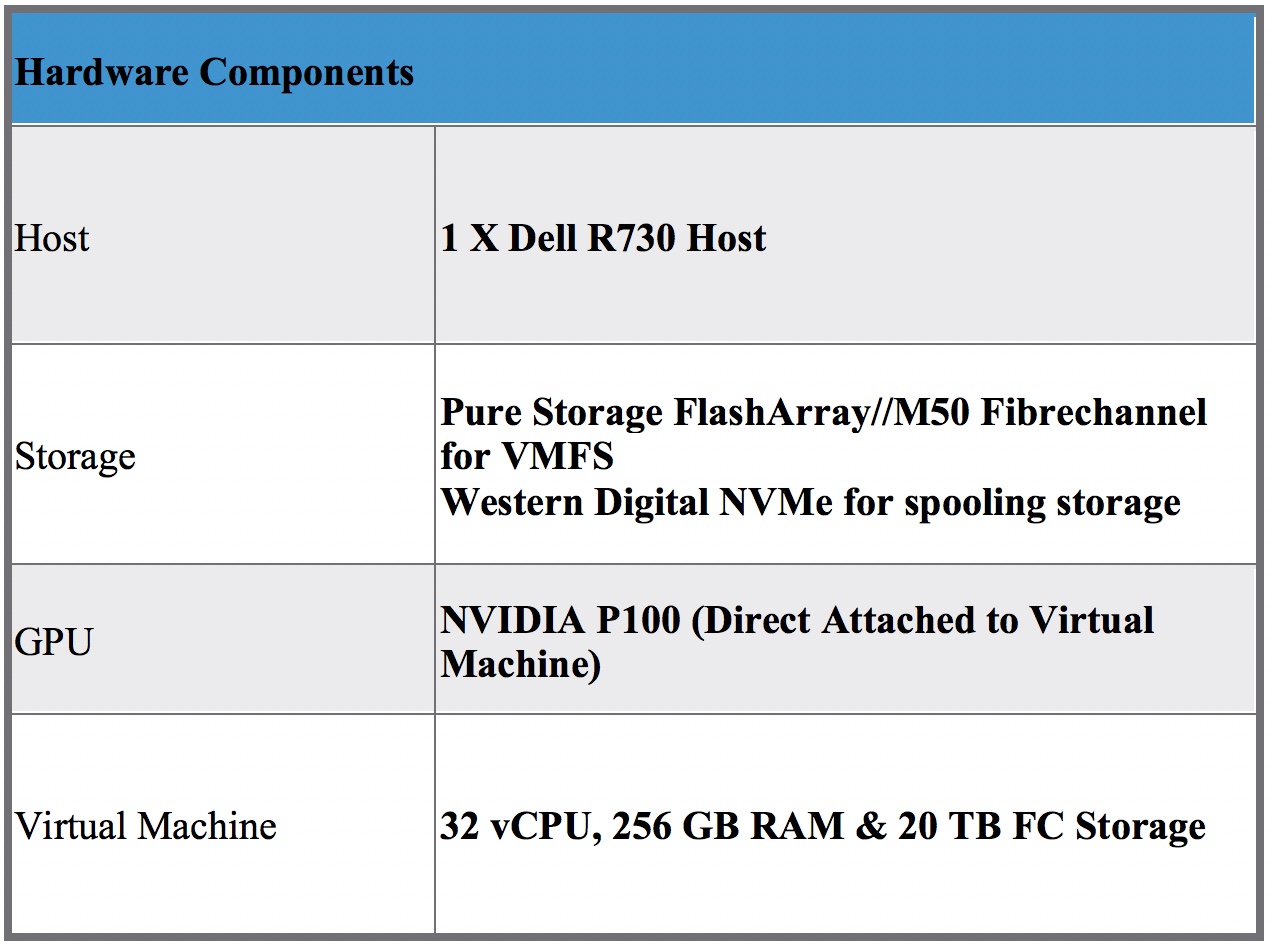

Table 1: Hardware Components used for validation

Table 2: Software Components used in Validation
Data Generation and Loading
The initial data was generated using the TPC-H dbgen utility with a scale factor of 10,000 by running the following command
./dbgen -s 10000
The total size of the raw data generated is about 10.5 TB.
Resulting table sizes and row counts
The size of the data generated and the breakdown by table and number of rows is shown.
[sqream@sqreamdb01 tpch10000]$ du -h *.tbl
230G customer.tbl
7.2T lineitem.tbl
4.0K nation.tbl
1.7T orders.tbl
1.2T partsupp.tbl
231G part.tbl
4.0K region.tbl
14G supplier.tbl
In part 2 of the blog we will look at the results from the validation of the vSphere virtualized SQream Database for data loading and querying.





