Software systems nowadays need to handle constantly changing load levels while being cost-effective. Peek load has always being a challenge, requiring a lot of spare capacity, and in recent years elasticity has proven itself as the best option.
Dynamically adjusting resources up or down to fit the current demand for the system is de facto the golden standard and benefits both the business and service provider. Scaling can be either vertical (adding more resources to a single node, e.g. more CPU and memory) or horizontal (adding more nodes in the system). The vertical scaling has some obvious limitations and scaling down is usually a problem.
In this blog post, we will present a horizontal autoscaling solution using:
- vCloud Director (vCD)’s native UI extensibility as management frontend
- vRealize Orchestrator (vRO) as backend.
- vRealize Operations (vROps) as monitoring system.
Contents
First, we have to decide what our solution architecture should be. As I’ve already mentioned, vCD will serve as a management interface, vRO will be the orchestration engine, and vROps the monitoring component.

There are two main flows:
- When the user manages (creates/deletes/updates) autoscaling rules:
- The user uses the vCD UI and the custom extension to perform the required tasks.
- The vCD UI extension uses API extension endpoint defined by vRO, which works through RabbitMQ notifications and makes it async by nature. This means, we can scale the vRO instances very easily.
- The vRO code that handles the notifications, either persists the changes requested by the user, or manipulates vROps domain objects to enable monitoring of resources.
- When monitoring event happens:
- vROps previously being configured to monitor the group of VMs to be autoscaled, triggers an alert.
- The alert is sent to vRO, which in our case would be an SNMP trap, which comes out of the box with vROps. But a more fitted approach would be to use an AMQP protocol and the RabbitMQ cluster for handling the notification.
- The vRO code handles the alert by scaling out or scaling in, based on the pre-configured definition.
The Solution
Let’s see how this will look like in reality.

The List of Rules
Our custom UI extension lists all created rules.

- Rule name – the name of the rule
- Template – the vApp template with a single VM inside
- Target vApp – is where are going to provision the new VMs
- Edge gateway – which holds the load balancer
- Pool name – the pool name of the load balancer
- Thresholds – the % of CPU and memory average usage, which would trigger either scale out or scale in

To define the custom APIs, we use an abstraction library to hide the AMQP massage handling complexity. We provide the method, the API URI, and the callback function to handle the request. For example, when the UI hits the https://<vcd.hostname>/api/org/:orgId/autoscale with HTTP request method GET, it will invoke the callback function which will return all rules.

vROps Symptoms and Alert Definitions
We need to have several things predefined before we can create the scaling objects:
- Group Type – the object type of our group, used to define metrics on.
- Two super metrics to enable us to monitor average CPU and Memory for the group of VMs:
- SM-AvgVMMemUsage →
avg(${adapterkind=VMWARE, resourcekind=VirtualMachine, metric=mem|usage_average, depth=1})
avg(Virtual Machine: Memory|Usage) - SM-AvgVMCPUUsage →
avg(${adapterkind=VMWARE, resourcekind=VirtualMachine, metric=cpu|usage_average, depth=1}) + avg(${adapterkind=VMWARE, resourcekind=VirtualMachine, attribute=cpu|readyPct, depth=1})
avg(Virtual Machine: CPU|Usage)+avg(Virtual Machine: CPU|Ready)
- SM-AvgVMMemUsage →
Finally, we have to enable our SuperMetrix in the default policy.
Symptom Definitions

Alert Definitions

The Rule Store
For the purposes of this post, the RuleStore will be backed as a plain JSON file, stored as a resource element in vRO. In reality, it might be backed as a SQL or NoSQL DB, depending on what type of operations you want to perform.

When an Alert Triggers
When an alert is triggered, for example because of high CPU load, a notification will be sent to vRO, which will take the appropriate action to scale out.

The vRO handler looks simple, because we use a library to abstract the SNMP notification. It provides a way to filter the trapMessage and an async action execution to perform the operation asynchronously.

The ScaleOut Operation
The action itself does 3 things:
- Deploys a New VM from a Template
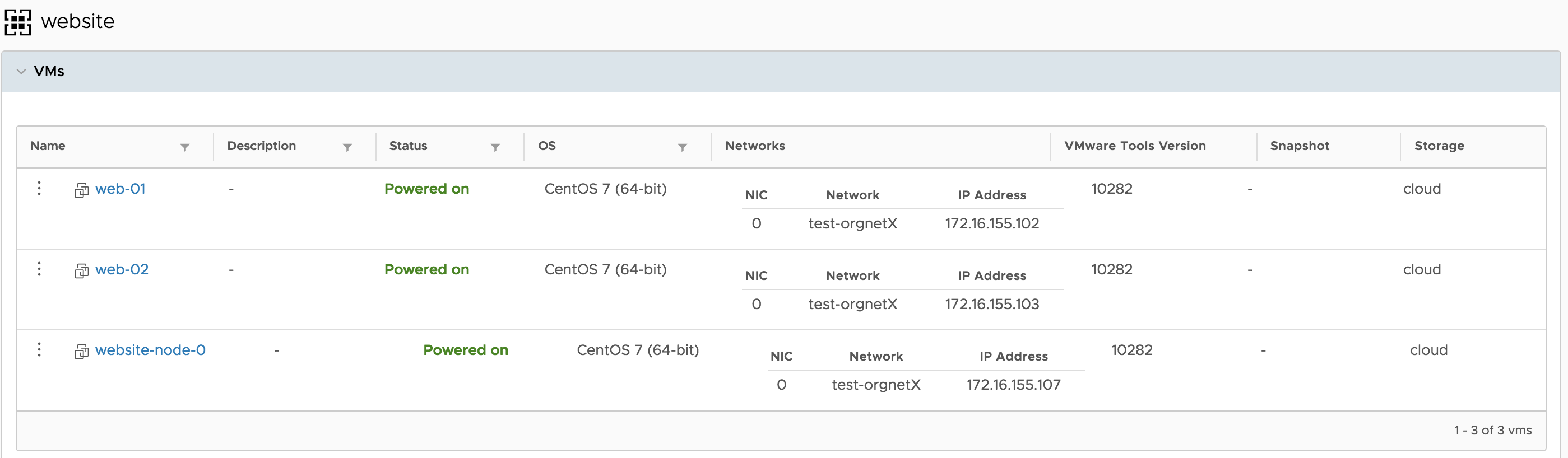
- Updates the preconfigured load balancer pool with the new member

- Updates the vROps group with the new machine.




The Result
The machine can now serve requests.






