Skip to content
LinuxPunx
Virtual Machine
Linux Articles
Developer
LinuxPunx
Toggle Menu
LinuxPunx
Linux Articles
Libsyn Podcast : Skills Upgrade #7
Linux Articles
Unlock the Easiest Path to HA SQL Server in Kubernetes
Linux Articles
Now supporting mod_lsapi for Nginx
Linux Articles
|
Uncategorized
SUSE’s Container Security Platform Now Listed in Amazon E…
Linux Articles
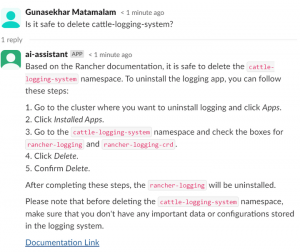
Harnessing AI in Rancher Prime 3.0: Shaping the Future To…
Linux Articles
What CentOS alternative distro should you choose?
Linux Articles
|
Uncategorized
Install your HPC Cluster with Warewulf
Linux Articles
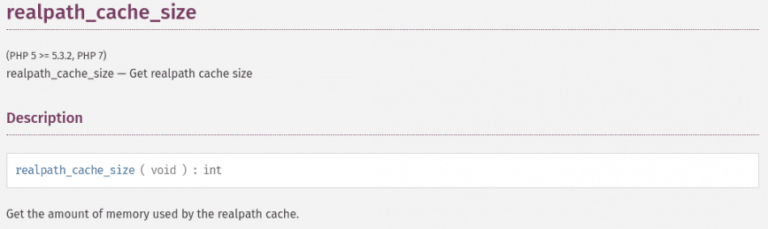
Set PHP realpath_cache_size ‘correctly’
Linux Articles
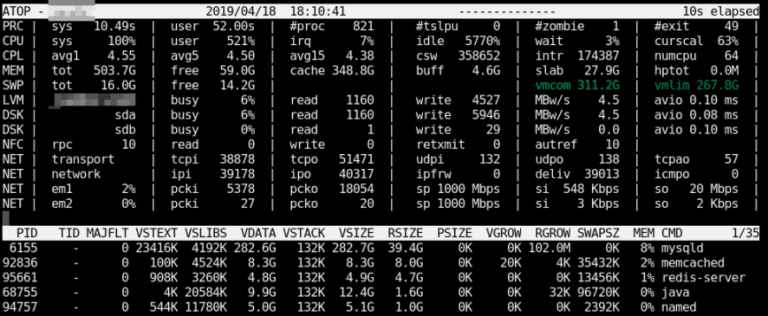
atop for Linux server performance analysis (Guide)
Linux Articles
Top Serverless Monitoring Tools + Serverless Resources
Linux Articles
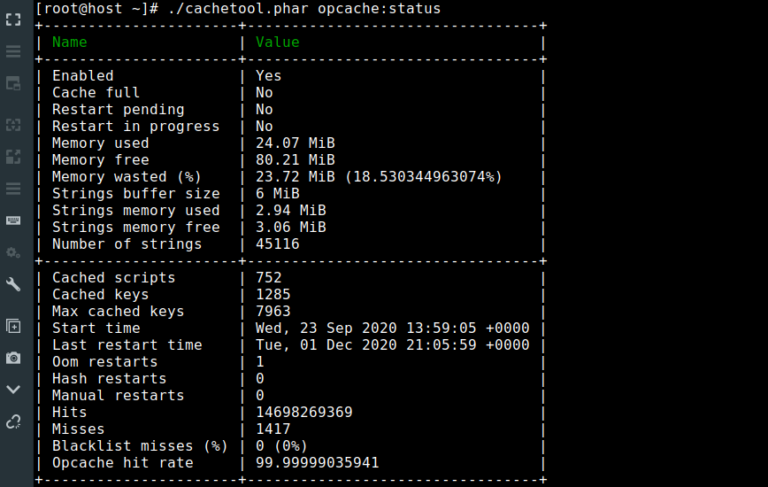
PHP performance: oPcache Control Panels
Linux Articles
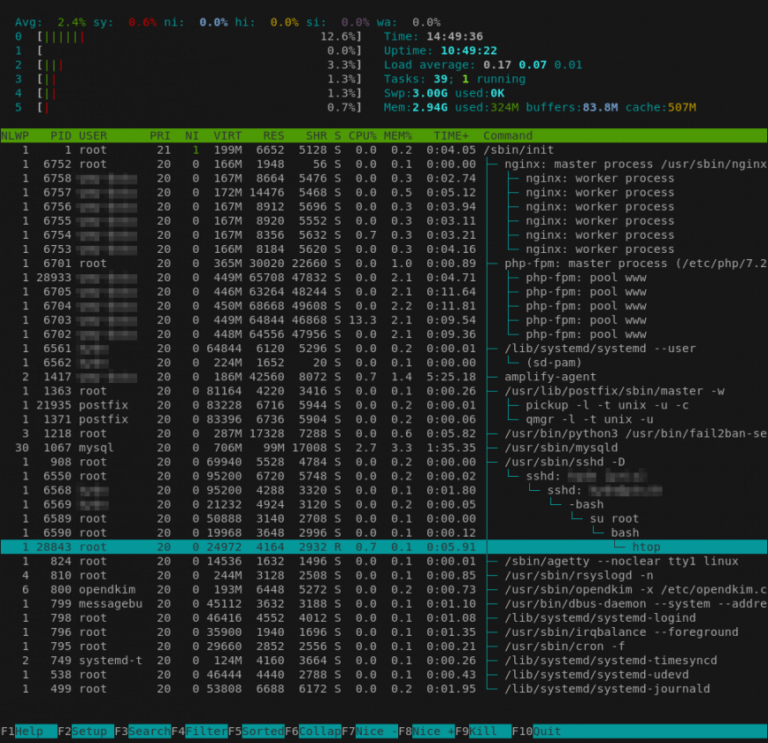
htop: Quick Guide & Customization
Page navigation
1
2
3
…
125
Next Page
Next
Scroll to top
Scroll to top
Virtual Machine
Linux Articles
Developer